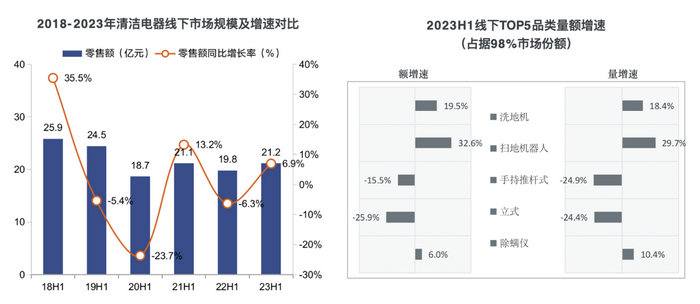
英文维基百科包含超过600万篇文章,所有其他语言的合并版本超过280亿个单词,超过309种语言的5200万篇文章。Wikipedia对于寻求知识的人来说是无与伦比的宝贵资源,但是它需要不断修剪的132,000名注册活跃月度编辑者。
为了寻找自主解决方案,麻省理工学院的研究人员开发了一种系统,该系统使用AI和机器学习来解决Wikipedia文章中的不一致之处。借助一系列算法,它可以识别错误并根据需要更新文章,使用来自网络的最新信息来生成经过修改的句子。
所讨论的算法是在包含句子对的数据集上进行训练的,其中一个句子是主张,另一个句子是相关的Wikipedia句子。每对都以以下三种方式之一进行标记:“同意”,表示句子包含匹配的事实信息;“不同意”,这意味着两者包含矛盾的信息;或“中性”,即两个标签均没有足够的信息。
系统将文章中过时的句子以及包含更新/冲突信息的“声明”句子作为输入。两种算法使繁重的工作变得困难重重,其中包括一个事实检查分类器,该分类器经过预先训练,可以用“同意”,“不同意”或“中立”标记数据集中的每个句子对。定制的“中立屏蔽器”模块可识别过时句子中的哪些词与权利要求相抵触,并删除最大化中立性所需的最小单词数,以便该对可以被标记为中立,然后在过时之后创建二进制“掩码”句子。
两个编码器/解码器框架会在掩蔽后生成最终的输出语句,以使该模型学习索赔和过时语句的压缩表示形式。然后,两个编码器/解码器协同工作,然后将不相似的单词滑入已删除单词留下的空缺位置,从而融合了权利要求中的不相似单词。
研究人员说,该系统还可以用于增强语料库,以在训练假新闻检测器时最大程度地减少偏见。一些检测器在句子对的数据集上进行训练,以通过将其与给定的证据进行匹配来学习验证要求。在这些对中,声明将使某些信息与来自维基百科的支持“证据”句子相匹配,或者将被修改为包括与证据句子相矛盾的信息。这些模型经过训练,可以通过反驳证据将主张标记为虚假,从而有助于识别虚假新闻。
在一个测试中,该团队使用了Wikipedia任务中的删除和融合技术来平衡数据集中的对并帮助减轻偏见。对于某些对,使用修改后的句子的虚假信息来重新生成支持句子的虚假证据。然后,某些关键短语同时存在于同意和不同意的句子中,这迫使模型分析更多功能。
研究人员报告说,他们的增强数据集使流行的假新闻检测器的错误率降低了13%。他们还说,在Wikipedia实验中,该系统在进行事实更新时更加准确,其输出与人类写作更加相似。
版权声明
本文仅代表作者观点,不代表本站立场。
本文系作者授权发表,未经许可,不得转载。